System Design: Easy way to keep Your API Endpoint Safe With a Failover Service for peak season - AWS CDN
3 min read
Are you using AWS Services for your API Endpoints? Are you unsure about the traffic and scalability issue with the system, even after configuring auto-scaling services?
Then this problem statement might be a good read for you. But first lets see if the use case matches your requirements.
Notes: This AWS solution is for single region, but can be scaled to multi zones.
What we have
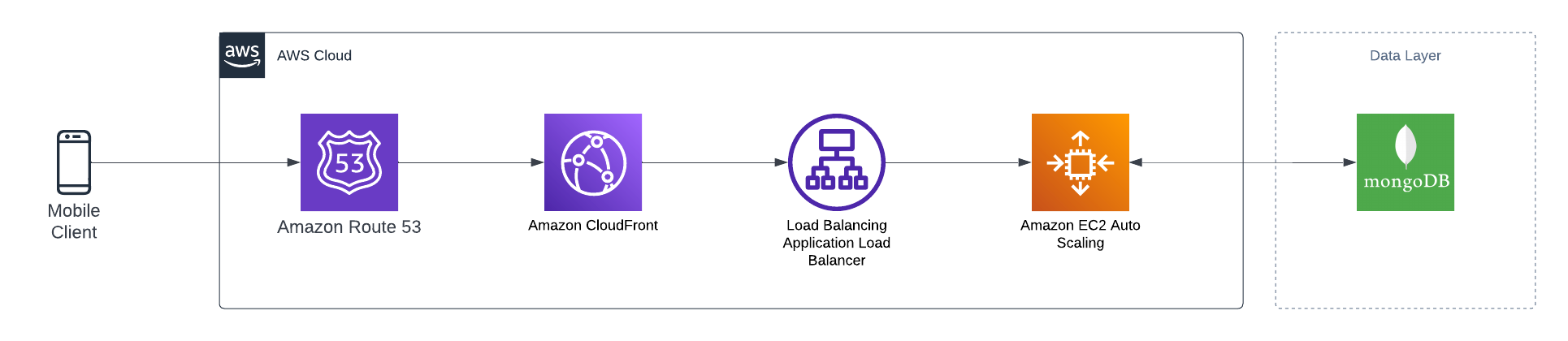
A large scale legacy system with a traditional Application load balancer and an autoscaling EC2 behind it.
Lets list down the services
- Route53. DNS routing
- Cloudfront. As the system is a monolith, all of its API endpoints is routed through Cloudfront, origin being the ALB
- Application load balancer
- Auto scaling EC2. Application layer connected to different services. All the API endpoints are read-only. (The solution was specific to my proof of concept, but it can be expanded to bigger solutions)
- MongoDB. Main database.
- Elastic Cache Redis. session dashboard caching for the application.
Here is what the system looks like
Problem 1
Due to huge amount of read-only request spike the database would go out of resources and would require vertical scaling, the problem with Atlas & vertical scaling it the application has to face a downtime.
Possible Solutions
- Scale up read replica, yes but only for a limit.
- Utilize Cloudfront caching, which was not possible for a longer duration of more then a minute as the data might change at any point of time, plus URL query parameters filtering would also hit the database.
- Utilize Cloudfront and invalidate cache, possible but not the quickest - cache invalidation can take up to 30 seconds + there is limit for free cache invalidations, and then you will be charged for each.
- Utilize elastic caching for endpoint, create observer and events for data changes and update at instant.
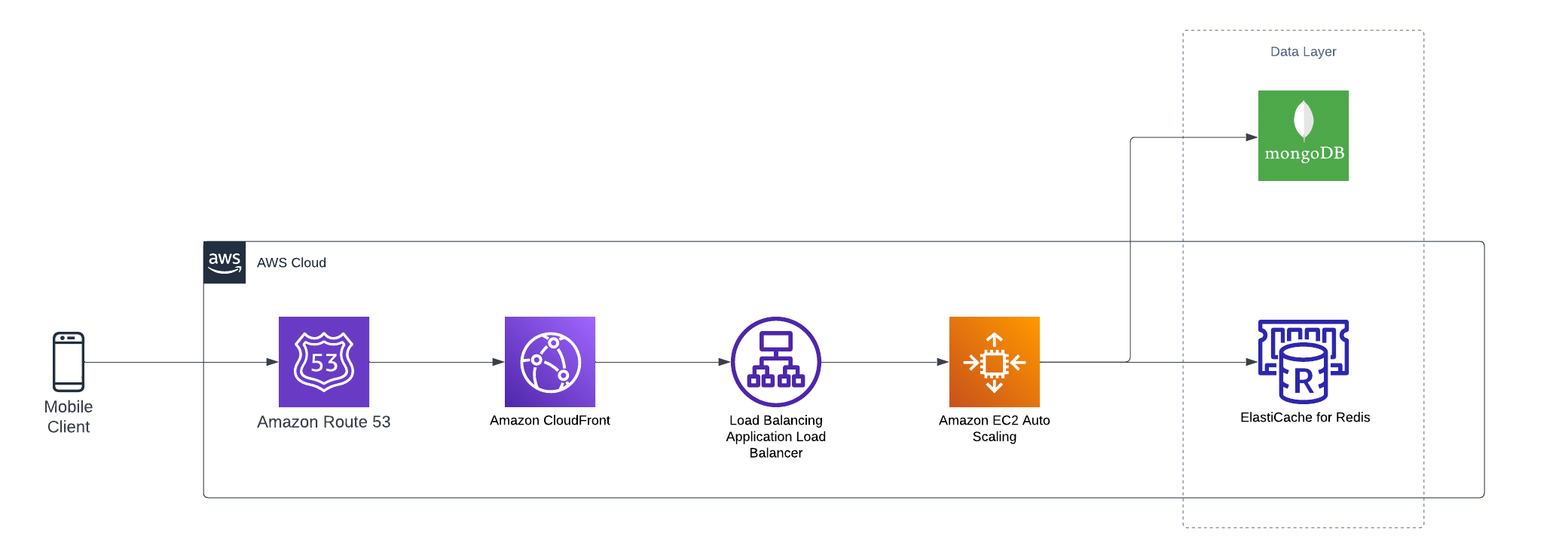
Solutions
- Database, increase read-replica set
- Utilizing elastic caching for endpoints and its query parameters, also leveraging cloudfront caching to its max as per the application and specific endpoints can handle for the dynamic data.
Here is what the updated design looks like
Problem 2
- Peak season traffic
- The application layer crashes due to high traffic, which can create a huge downtime.
- EC2’s are overloaded and can run unhealthy
Solutions
- Have a failover service B which would keep the system up and running and give a breathing space for service A to come back online.
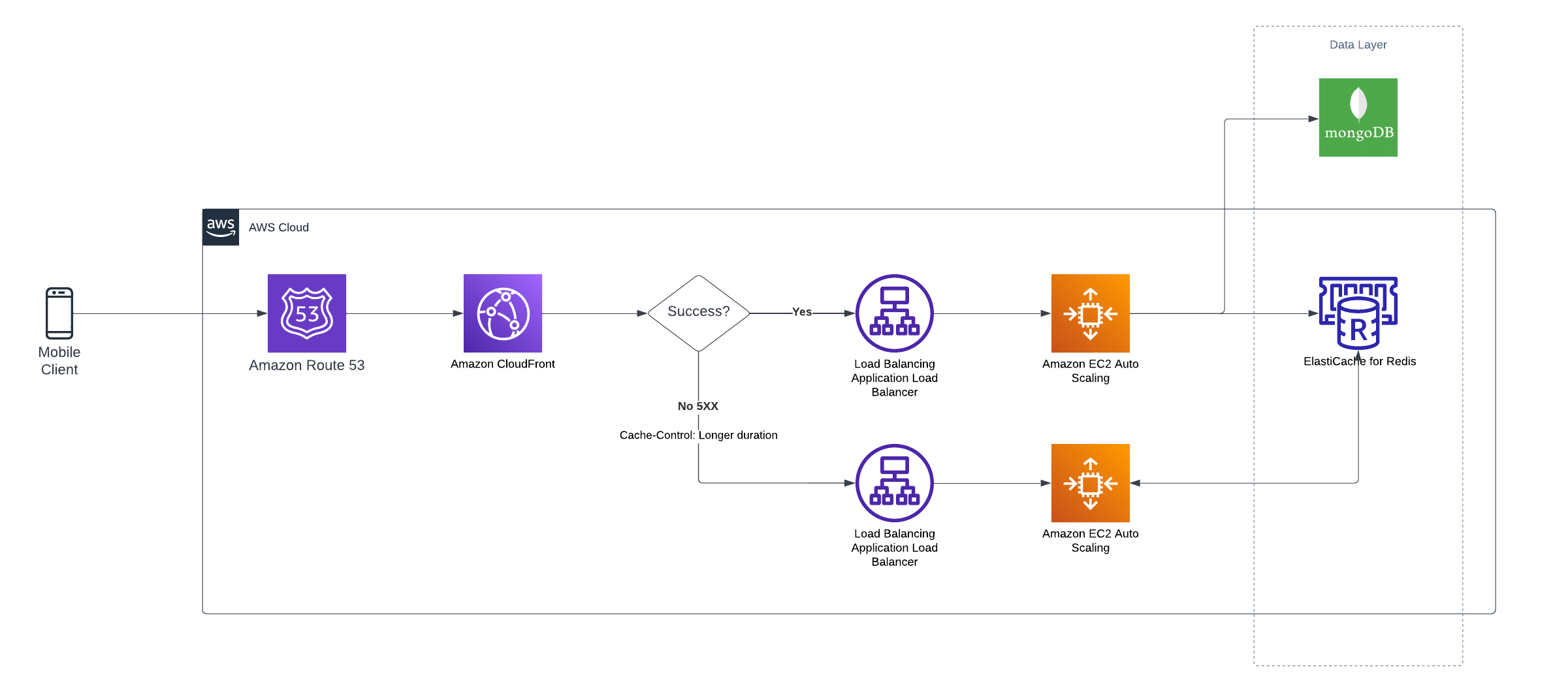
Solution 1
- If you have used hashing for caching the endpoints with query, you might as well only leverage the Elastic cache redis in this case for service B
- With above case, service B can be light weight Lambda@Edge OR easy stack like NodeJS for I/O operations.
- Add added additional time to cache on cloudfront with Control-Cache response headers to more then 300 seconds.
Here is what the updated design looks like
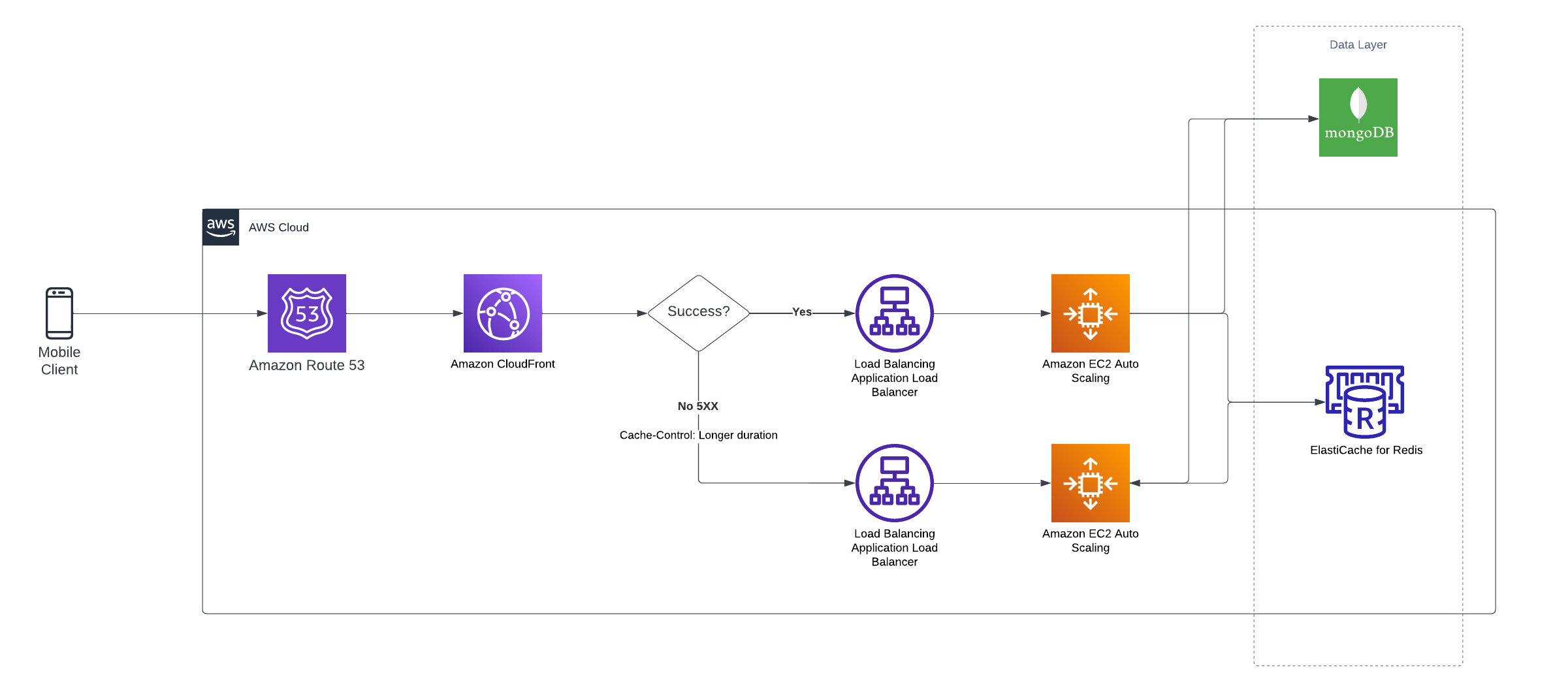
Solution 2
- Replicate the whole system as service A to service B
- We can also make use of only read replica set of database.
- Add added additional time to cache on cloudfront with Control-Cache response headers to more then 300 seconds.
Here is what the updated design looks like
AWS Documentation on configuring the Cloudfront for failover.
Alternatives
In case of database failure of service A, wou should also make use of separate database for service B. In that case you will require to make use of observers and events to sync between the databases.
Understand that service B (Plan B) is always not good and you should try to avoid it as much as possible, reason being it shows that you are not confident about the service A (Plan A).
The above post is for quick solutions for the peak traffic. Team should always revisit the tech debts in the system and try to improve on it in service A itself.